Interactive concordance
Working with the William Carlos Williams society to design and develop a searching tool.The WCW society reached out to me about building a custom concordance for the Author's collected works. In college I took a database class that focused on Oracle SQL. I wanted to use this project to learn and because I had already taken a deep dive into Oracle, I decided to use MySQL.
Database design
There are three tables, one to store metadata about line entries, one to store each line, and another to store each unique word and their frequency rank.
create table info(
id int not null auto_increment,
collection varchar(100),
book varchar(100),
section varchar(100),
title varchar(150),
kind int,
year int,
primary key(id));
create table line(
id int not null auto_increment,
info_id int not null,
text varchar(1000),
page_num int,
stanza_num int,
line_num int,
primary key(id),
foreign key(info_id) references info(id));
create table word(
id int not null auto_increment,
word varchar(25),
freq int,
w_rank int,
primary key(id));
Backend
The backend requirements were determined by the existing site, a relatively simple, Wordpress based project. I tried to figure out the best way to develop and test the tool but also create an easy deployment pipeline. This was relatively straighforward and I created a HTML landing page and attached the form to a backend script written in PHP.
The backend connects to and queries the database and the results were returned directly to the page. It starts by getting the values from the values from the post request.
$search_terms = stripslashes($_POST["value"]);
$search_type = $_POST["search_type"];
$match_case = $_POST["match_case"];
$collection = $_POST["collection"];
$sort_by = $_POST["sort_by"];
The dynamic nature of the queries required me to build the query in the script. I start with the base query, and add necessary pieces based on form input and filter choices. These are the query pieces.
$query =
"select info_id, title, text, page_num, stanza_num, line_num, year
from line inner join info on line.info_id=info.id
where";
$mc = " cast(text as binary) regexp binary ?";
$nmc = " text regexp ?";
$cpIII = " and info_id < 846";
$cpI = " and info_id < 390";
$cpII = " and info_id > 389 and info_id < 846";
$pat = " and info_id > 845 and info_id < 862";
$bwom = " and info_id > 861";
$al = " order by title, line_num, page_num";
$rev = " order by title desc, line_num, page_num";
$dotn = " order by year, title, line_num, page_num";
$dnto = " order by year desc, title, line_num, page_num";
$and = " and";
The checks and building are handled like this
if ($match_case == "on")
$query .= $mc;
else
$query .= $nmc;
if ($search_type == "multi_term") {
for ($i = 1; $i < count($cleaned_search_terms); $i++) {
if ($match_case == "on")
$query .= $and . $mc;
else
$query .= $and . $nmc;
}
}
if ($collection == "CV")
$query .= $cpIII;
if ($collection == "CPI")
$query .= $cpI;
if ($collection == "CPII")
$query .= $cpII;
if ($collection == "Paterson")
$query .= $pat;
if ($collection == "BWOM")
$query .= $bwom;
if ($sort_by == "alphabetical")
$query .= $al;
if ($sort_by == "reverse_alphabetical")
$query .= $rev;
if ($sort_by == "old_to_new")
$query .= $dotn;
if ($sort_by == "new_to_old")
$query .= $dnto;
I haven't done much production database work so I opted to sanitize almost every special character from the input. I also use prepared statements to help guard against injection attacks.
function sanitize_input($input, $search_type) {
global $terms;
if (strlen($input) < 2) {
exit("Invalid:\nSearch input must be 2 or more characters");
}
$invalid_input = "/[^a-zA-Z0-9'\",\- ]/";
if ($search_type == "single_term") {
$invalid_input = "/[^a-zA-Z0-9'\",-]/";
}
if (preg_match($invalid_input, $input)) {
return "INVALID";
}
if ($search_type == "phrase") {
array_push($terms, $input);
return [$input];
}
else if ($search_type == "single_term") {
array_push($terms, $input);
return ["[^a-zA-Z]".$input."[^a-zA-Z']"];
}
else if ($search_type == "multi_term") {
$res = explode(" ", $input);
$result = array();
foreach ($res as $term) {
array_push($terms, $term);
array_push($result, "[^a-zA-Z]".$term."[^a-zA-Z']");
}
return $result;
}
}
Example:
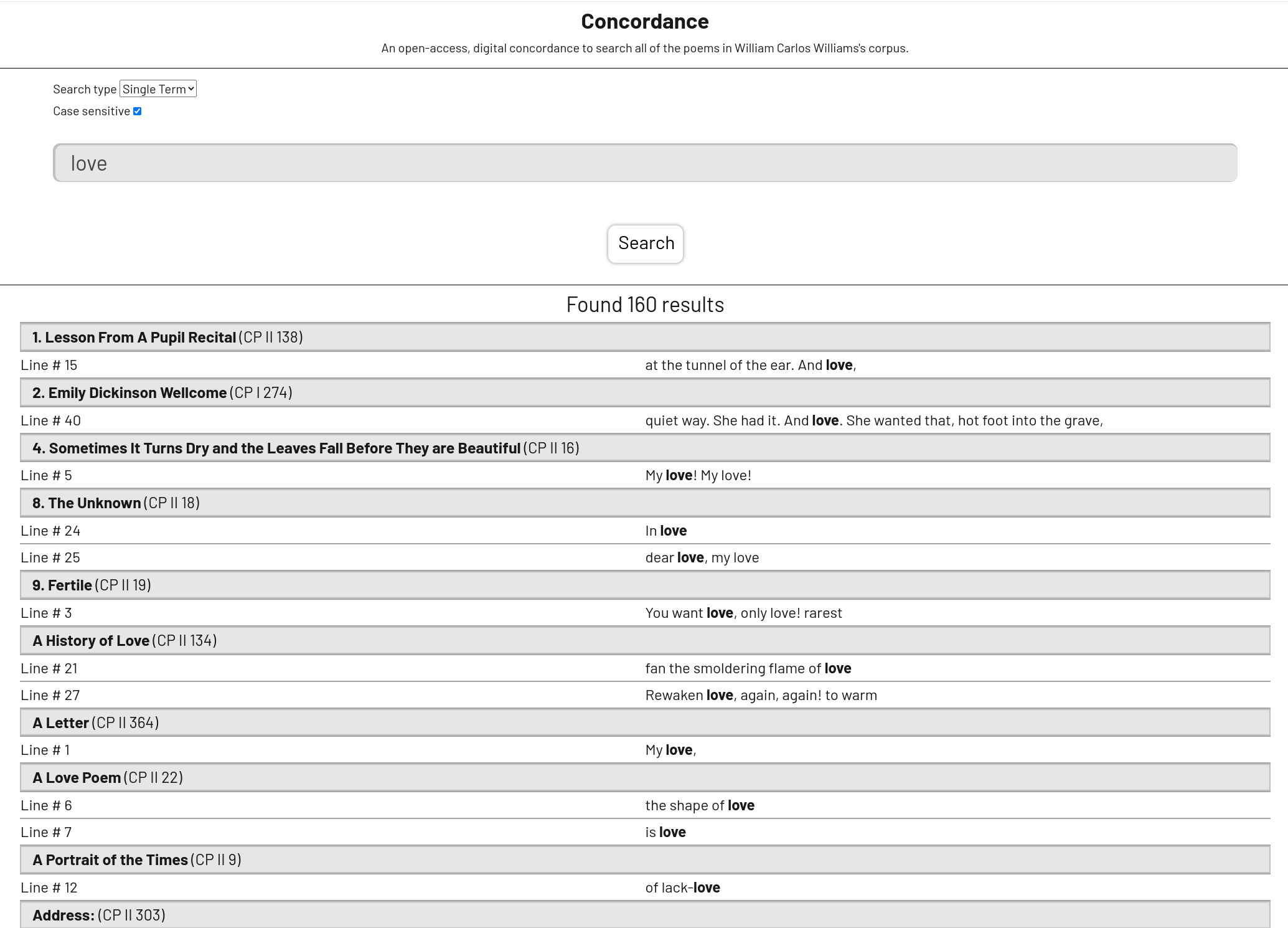
Calculating word frequencies
I used a sed replace to extract all the lines from my database setup scripts.
$ sed "s/.\" \(.*\) \".
/\1/" lines_final.sql >> only_text.txt
$ sed -i -e "1,/values/d" -e "1,/values/d" only_text.txt
I then used a small python script to calculate the frequencies of all unique words.
words = {}
for line in open("only_text.txt"):
for word in line.split():
word = word.strip(" |:;,./!?'\"\\[]{}—-_=+~`<>()@#$%^&*").lower()
if (len(word) <= 1):
if word not in words:
words[word] = 1
else:
words[word] += 1
s = sum(words.values())
for item in sorted(words.items(), key=lambda x:x[1]):
print("%15s -- %5d -- %5.4f%s" % (item[0], item[1], 100*item[1]/s, "%"))
print("Total words : %7d" % s)
print("Unique words: %7d" % len(words))
There are a total of 19159 unique words in the corpus (doesn't include titles).
Data cleaning
Preparing the data for the database was very tedious. Each book was in pdf format so I used an online pdf-to-text convertor to get plain text files. The conversion was decent but there were a lot of oddities and filler characters that needed to be removed.
This is where my use of vim came in handy. Search and replace, along with macros, are such powerful tools. Without these, I would have had a much more difficult time. I also used some bash scripts (mostly using sed) to help with processing. There were also a couple python scripts I wrote to automate some of the process.
This is a script that takes a type of processed file and converts it into sql insert statements. Each section had been prepended with a '*' character as well as the title. Stanza numbers and line numbers are automatically calculated.
for line in file:
if line.startswith('*'):
new_file.write("\n")
words = line.split()
stanza_num = 1
line_num = 1
info_id = words[0][1:]
page_num = words[1]
continue
if len(line.strip()) == 0:
stanza_num += 1
else:
new_file.write(
"(null, " +
str(info_id) +
", \" " +
line.rstrip() + " \", " +
str(page_num) +
", " + str(stanza_num) +
", " + str(line_num) +
"),\n")
line_num += 1
This is a recursive macro that I used to wrap processed lines from one collection into the correct format for inserting into the database.
I(null, 0, ^[A);^[j@q